Conditional Clustering using LLMs

Summary
I gathered five short texts that can be grouped by topic, sentiment, or emotion. I tested three methods: (1) task-specific LLM embeddings, (2) GPT-4 with prompts, and (3) a TF-IDF + K-Means baseline. I compared how each method clusters the same inputs under different conditions. The third method does not allow for defining a condition explicitly.
About the Data
Five short texts designed to be clusterable in multiple ways (sports/finance/science for topic; positive/neutral/negative for sentiment; joy/sadness/etc. for emotion). This makes it easy to see how the “definition of similarity” affects grouping.
- “The soccer team celebrated their championship victory with a parade.”
- “The marathon runner collapsed just meters away from the finish line.”
- “Basketball players need both speed and strategy to dominate the court.”
- “The stock market experienced a sharp decline today, causing panic among investors.”
- “NASA just launched a new telescope to explore distant galaxies.”
Methods
Task-specific LLM embeddings + K-Means, using:
cardiffnlp/tweet-topic-21-multifor topic classificationj-hartmann/emotion-english-distilroberta-basefor emotion classificationcardiffnlp/twitter-roberta-base-sentimentfor sentiment classification
Prompt-based GPT-4 approach: I used GPT-4 to generate sentence groupings based on natural language prompts specifying topic, emotion, or style. Since GPT-4 doesn’t expose its internal embeddings, I used text-embedding-ada-002 to embed the same texts and perform clustering aligned with each condition.
Classical baseline: TF-IDF + K-Means (no way to define the condition directly).
Evaluation
PCA views of the embeddings
Topic shows tighter, clearer groupings; sentiment and emotion are more diffuse (they are more subjective), so clusters spread out more.
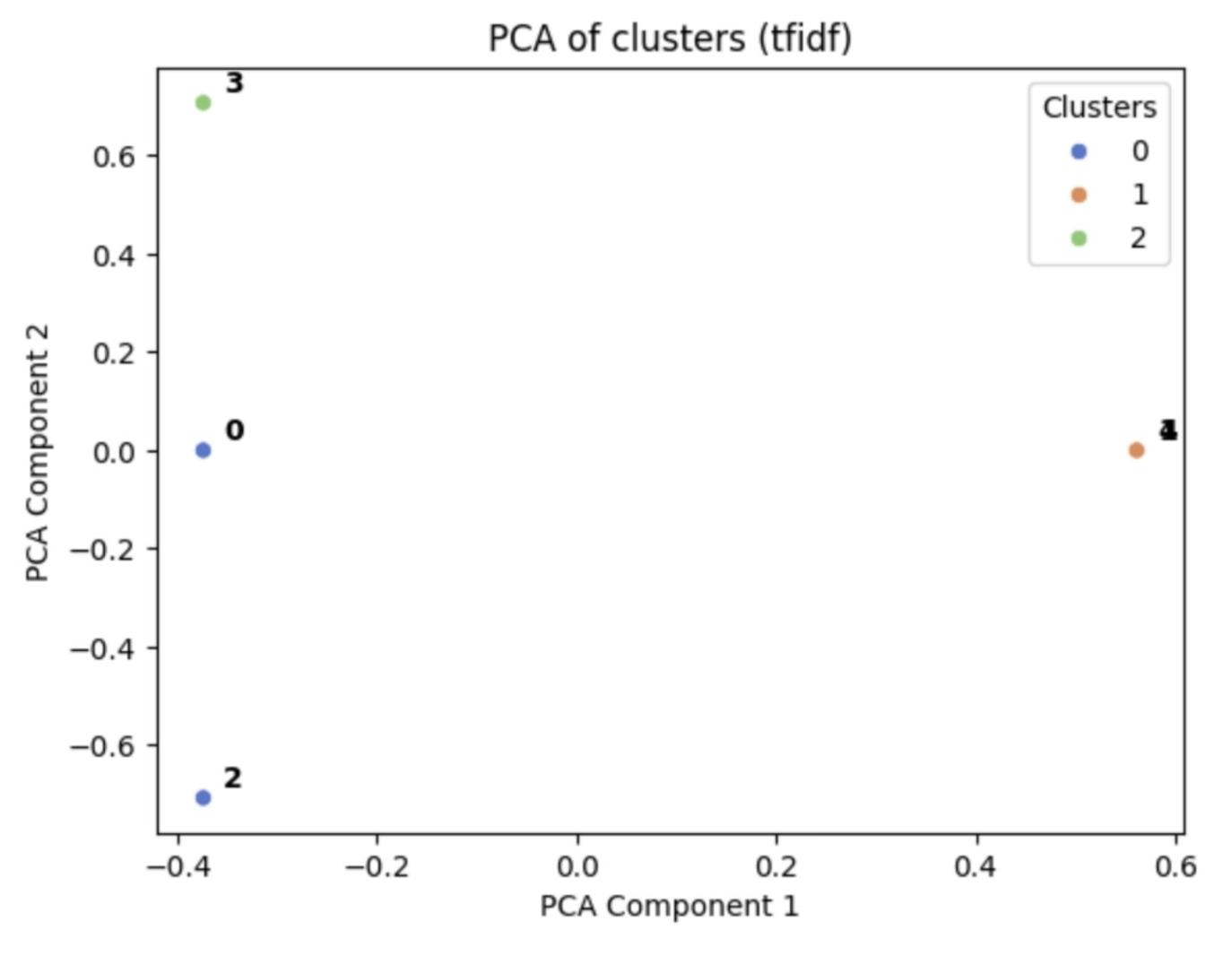
K-Means on LLM embeddings vs. TF-IDF
Clustering with LLM embeddings often grouped the sentences in ways that matched the intended condition (like topic or emotion). In contrast, TF-IDF sometimes grouped unrelated sentences together just because they shared common words.
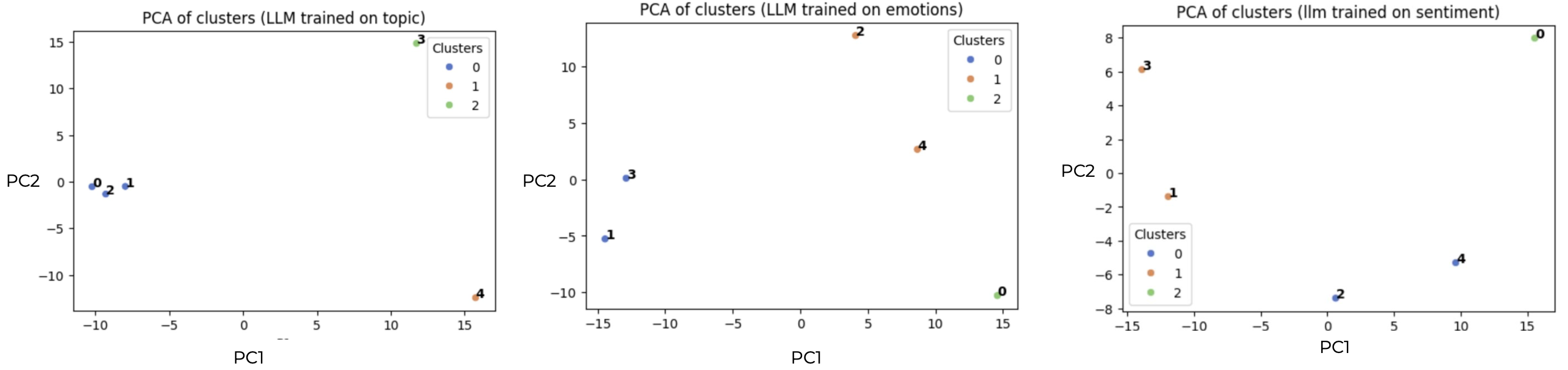
Do the embedding spaces agree?
Not exactly. Each LLM I used was fine-tuned on a specific task (topic, sentiment, or emotion) and trained to produce embeddings aligned with those labels. As a result, the same sentences cluster differently depending on which model is used. For conditional clustering, using task-specific LLMs gives you embeddings that naturally reflect the condition you are interested in.
Insights
- LLMs trained on a specific task give embeddings that naturally reflect that task, so clustering works better.
- TF-IDF is simple but does not account for meaning, it just picks up on word overlap, which can be misleading.
- Using GPT-4 with prompts is helpful when no pre-trained model fits, as long as the condition can be explained clearly.