How do LLMs and classical methods classify Amazon reviews?

Summary
Classify Amazon reviews into categories using both LLMs and classical ML models. I used the following methods:
- Classical models:
- Multiclass Logistic Regression on TF-IDF feature space
- Random Forest on TF-IDF feature space
- LLM:
- Fine-tuned DISTILBERT on the review dataset
I did error analysis of highly misclassified categories (e.g., Office Products vs Electronics) using PCA, t-SNE, Monte Carlo Dropout, and LDA.
About the Data
From the large Amazon Reviews dataset, I selected 5,000 samples from each of the following six product categories. I chose these categories to introduce variation in topic, tone, and sentiment across the reviews:
- Beauty & Personal Care
- Books
- Electronics
- Grocery & Gourmet Food
- Toys & Games
- Office Products
Data source: Amazon Reviews 2023 (McAuley Lab)
Methods
I compared two approaches: classical models using TF-IDF features (Logistic Regression and Random Forest) versus a fine-tuned DistilBERT.
For the LLM method, I fine-tuned the distilbert-base-uncased model on my Amazon reviews dataset.
I used a 70/30 train-test split for all models, and applied balanced sampling to ensure each product category was equally represented.
Evaluation
| Model | Train Accuracy | Test Accuracy |
|---|---|---|
| Logistic Regression (TF-IDF) | 0.87 | 0.84 |
| Random Forest (TF-IDF) | 0.86 | 0.80 |
| DistilBERT (fine-tuned) | 0.95 | 0.88 |
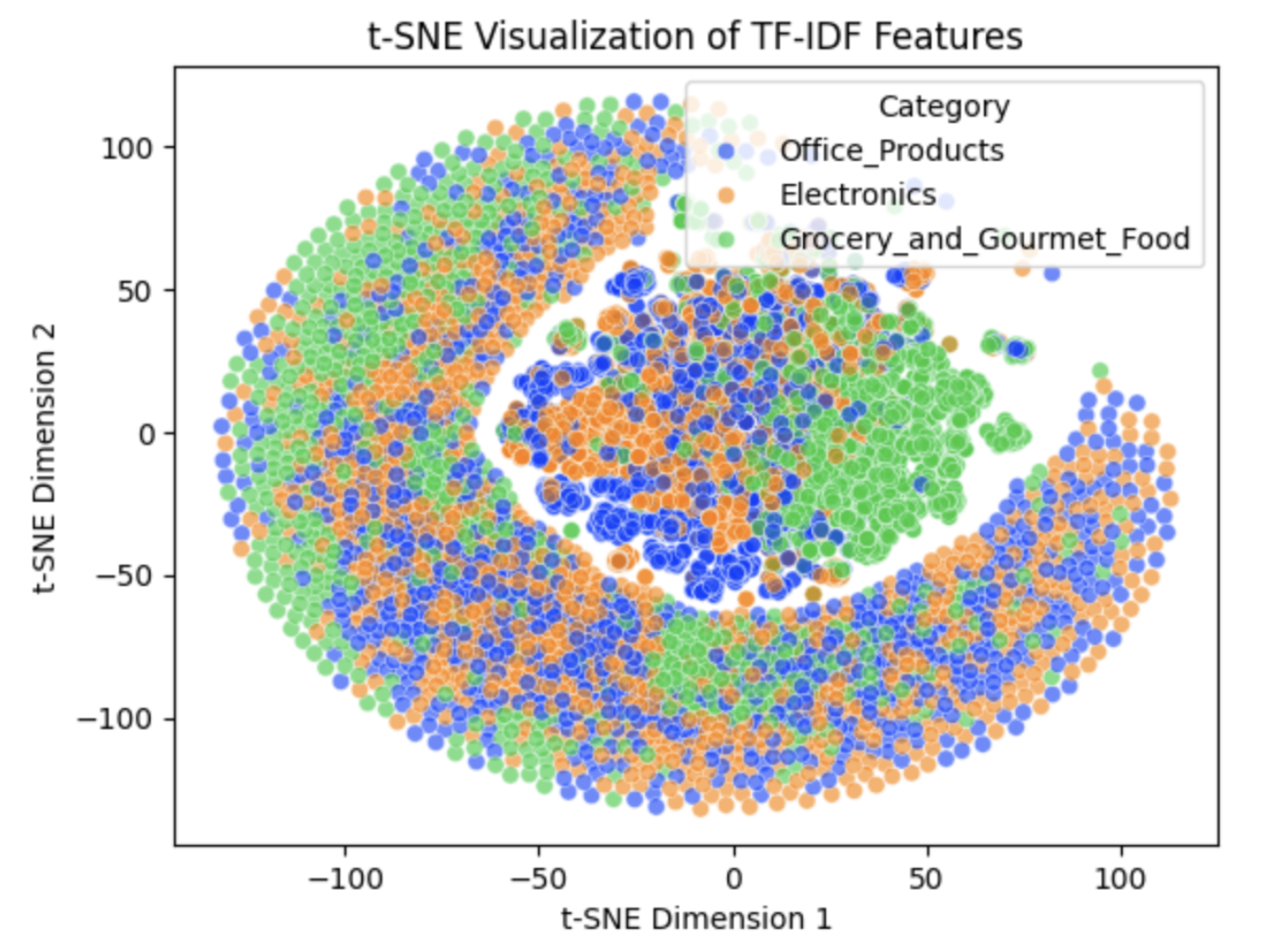
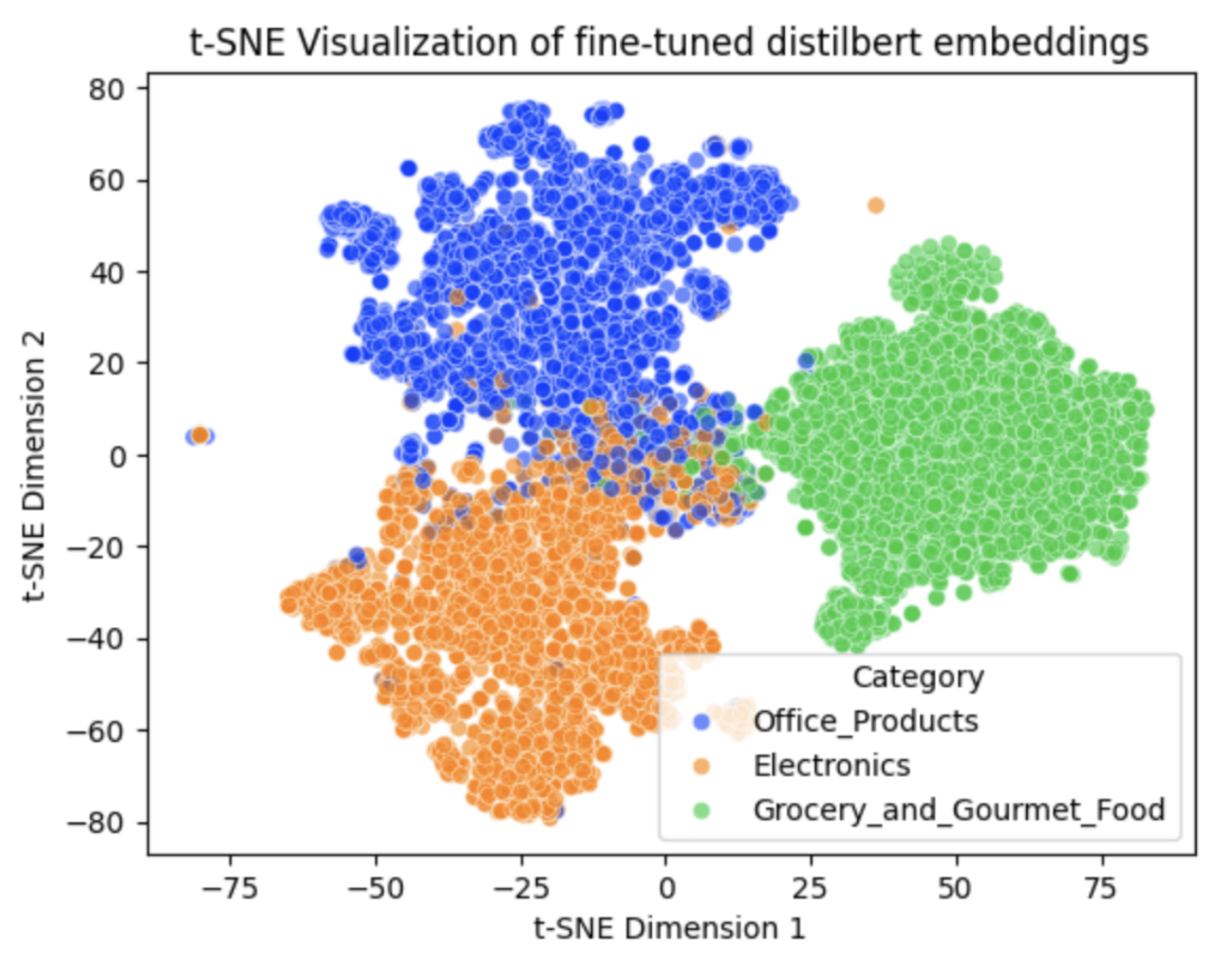
DistilBERT performs the best overall, although there are some signs of overfitting. All models struggle the most with the Electronics and Office Products categories, which have the highest number of misclassifications. In contrast, Grocery & Gourmet Food shows the fewest misclassifications. This contrast makes these categories a useful pair for visualizing how mixed the class boundaries appear after t-SNE transformation.
Short, generic reviews (like “Great product, works fine”) lack clear anchors, so the models tend to guess more. Below is a view of review length vs. prediction.
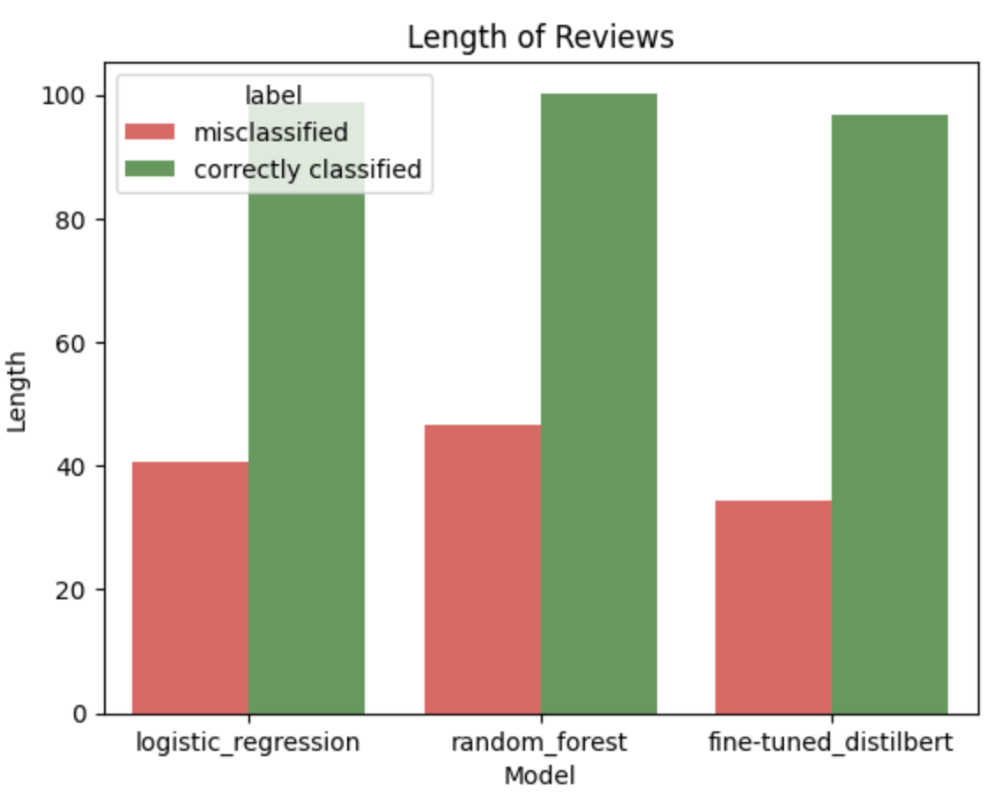
Insights
To see the difference between bag-of-words vs contextual embeddings, I plotted t-SNE for TF-IDF and for DistilBERT embeddings. TF-IDF shows heavy mixing, especially Office/Electronics. DistilBERT reveals tighter groups; Grocery is notably well-separated.
A quick look at DistilBERT’s [CLS] attention maps: correct cases highlight product-specific terms; misclassified pairs lean on generic sentiment or accessory words that appear in multiple categories.
![[CLS] attention — correct case](../images/attention-correct.png)
![[CLS] attention — misclassified case](../images/attention-misclassified.png)